
GBRank:一种基于回归的学习排序算法
GBRank是一种pairwise的学习排序算法,他是基于回归来解决pair对的先后排序问题。在GBRank中,使用的回归算法是GBT(Gradient Boosting Tree),可以参考这个,pairwise相关的可以参考这个
算法原理
一般来说在搜索引擎里面,相关性越高的越应该排在前面。现在query-doc的特征使用向量$x$或者$y$表示,假设现在有一个文档对$\left \langle x_i,y_i \right \rangle$,当$x_i$排在$y_i$前面时,我们使用$x_i \succ y_i$来表示。
我们含顺序的pair对用如下集合表示(也就是真的$x_i$真的排在$y_i$前面):$$S=\{ \left \langle x_i,y_i \right \rangle | x_i \succ y_i,i = 1…N \}$$
现假设学习的排序函数为$h$,我们希望当$h(x_i)>h(y_i)$时,满足$x_i \succ y_i$的数量越多越好.
现在将$h$的风险函数用如下式子表示:$$R(h) = \frac{1}{2} \sum_{i=1}^N \left( max\{0,h(y_i)-h(x_i)\} \right)^2$$
从$R(h)$可以知道知道每个pair对$\left \langle x_i,y_i \right \rangle$的cost为:
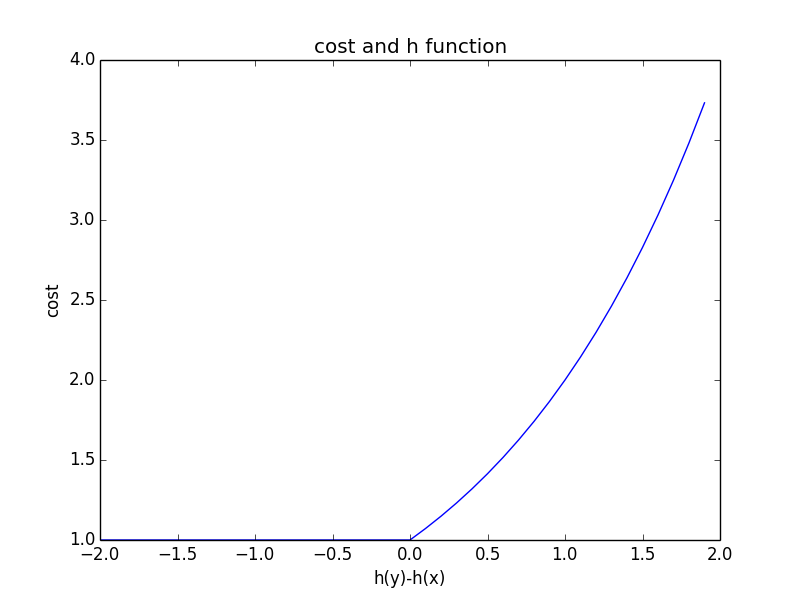
可以发现当:
- $h(x_i) \geq h(y_i)$,cost代价为0,也就是并不会对最终的风险函数的值产生影响
- $h(x_i) < h(y_i)$,cost代价为其差值的平方
上述风险函数直接优化比较困难,这里一个巧妙的解决方案时使用回归的方法,也就是$x_i$或者$y_i$去拟合他们另个预测值目标。
为了避免优化函数$h$是一个常量,风险函数一般情况下会加上一个平滑项$\tau$($0 < \tau \leq 1$):$$R(h,\tau ) = \frac{1}{2} \sum_{i=1}^N \left( max\{0,h(y_i)-h(x_i)+\tau \} \right)^2 -\lambda \tau^2 $$
因为当$h$为常量函数时,先前的$R(h)=0$就没有再优化的空间了
其实加了平滑项就变相的转为:如果希望$x_i \succ y_i$,就得有$h(x_i) > h(y_i)+\tau$,也就是更为严格了,多了一个gap
对于$R(h)$计算$h(x_i)$和$h(y_i)$的负梯度为:$$max\{0,h(y_i)-h(x_i)\} \quad,\quad -max\{0,h(y_i)-h(x_i)\}$$
可以发现当pair对符合$\left \langle x_i,y_i \right \rangle$的顺序时,上述的梯度均为0,对于这类case就没有必要在去优化了(以为已经满足目标了),但是对于另一类,如果$h$不满足pair$\left \langle x_i,y_i \right \rangle$,他们对应的梯度为:$$h(y_i)-h(x_i) \quad,\quad h(x_i)-h(y_i)$$
因为此时$h(y_i)>h(x_i)$
还有对于上面两个梯度的后面那个式子存在的意义不是很理解-_-
到了这儿,我们知道所谓的训练样本就是对于$x_i \succ y_i$但是$h(y_i) > h(x_i)$,并且使用的是回归方法,GBRank为其巧妙的找了训练的目标:$x_i$的目标为$h(y_i)+ \tau$以及$y_i$的目标为$h(x_i)- \tau$,也就是在每次迭代是将会构建以下训练集:$$\{(x_i,h(y_i)+\tau),(y_i,h(x_i)-\tau)\}$$
算法步骤
GBRank使用GBT为回归函数,所以整个GBRank的算法过程为:
Input:
- 训练数据集,真实的排序pair对$S=\{(x_1,y_1),(x_2,y_2)…(x_N,y_N)\}$
- 迭代的次数:$K$
Output:
- 最终模型$h(x)$
Procedure:
- 随机初始化为一个函数$h_o$
- 循环$k \in \{1….K\}$
- 使用$h_{k-1}$作为近似的$h$函数,我们将对样本的计算结果分到两个不相交的集合:$$S^+=\{\left \langle x_i,y_i \right \rangle \in S | h_{k-1}(x_i) \geq h_{k-1}(y_i)+\tau \}$$和$$S^-=\{\left \langle x_i,y_i \right \rangle \in S | h_{k-1}(x_i) < h_{k-1}(y_i)+\tau \}$$
- 使用
GBT对下面的数据集拟合一个回归函数$g(x)$:$$\{(x_i,h_{k-1}(y_i)+\tau),(y_i,h_{k-1}(x_i)-\tau) | (x_i,y_i) \in S^- \}$$ - 进行模型的更新:$$h_k(x) = \frac{kh_{k-1}(x)+\eta g_k(x)}{k+1}$$其中$\eta$为收缩因子
- 输出最终的模型$h_k(x)$
注意了,其实这里的回归函数还可以使用其他的回归函数来代替,比如$Linear Regression$之类的
总结
$h(x)$为最终的排序函数,GBRank在训练时每次迭代中将$h_k(x)$的排序结果与真实结果不一样的样本(就是分错的样本)单独拿出来做训练样本,并且其训练目标为pair的另一个预测值作为回归目标,非常巧妙。
此时重新看这个GBRank模型与AdaBoost、GBT其实很大同小异,都是将上一次训练中分错的样本再拿来训练,也是一个提升的模型
在其paper中的实验结果也是要略好于$RankSvm$,但是其比较疼的时其训练还是比较复杂的,或者说比较耗时,其预测也会比较麻烦一点,所以使用时得慎重~
参考
[1]. 2007-GBRank-A Regression Framework for Learning Ranking Functions Using Relative Relevance Judgments
本作品采用[知识共享署名-非商业性使用-相同方式共享 2.5]中国大陆许可协议进行许可,我的博客欢迎复制共享,但在同时,希望保留我的署名权kubiCode,并且,不得用于商业用途。如您有任何疑问或者授权方面的协商,请给我留言。
